前言
最近在 B 站上刷到了到一个视频 【教程】如何将自己的logo印在音乐上?,感觉有点意思,于是探究了一下原理。
声谱图原理
Spek 等软件可以查看音频的声谱图。这里以 Foobar 2000 插件为例,可以看到声谱图的横轴代表时间,然后纵轴代表频率,颜色从紫色到红色由浅到深代表这个频率上的能量。
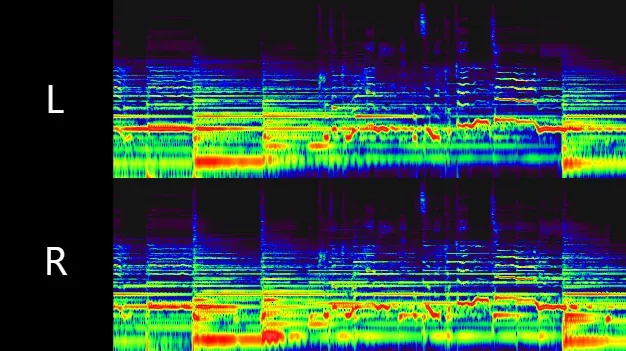
也就是说,声谱图把声音摊开成了一个二维平面:

生成声谱图常用的方法叫短时傅里叶变换(STFT)。
普通傅里叶变换可以告诉我们一段信号里有哪些频率成分。但如果直接对整首歌做一次傅里叶变换,结果只会告诉我们整首歌总体上有哪些频率,不会告诉我们这些频率分别在什么时候出现。
STFT 的办法很朴素:先取一小段音频窗口,对这一小段做傅里叶变换,再往后移动一点窗口,重复这个过程直到分析完整首歌曲。
这样就能得到一张“频率 - 时间表”。每一个格子里是一个复数,通常写成:
其中:
- : 原始音频采样率
- : 窗函数
- : 第几个时间帧
- : 第几个频率 bin
- : hop length,也就是相邻两帧之间的步长
- : FFT 长度
这个复数可以拆成两部分:
其中 是幅度, 是相位。
声谱图主要看的是幅度。为了显示方便,很多工具会把幅度转成分贝:
表示一个很小的数,以避免对 取对数。
要做的声谱图水印,主要就是修改 ,即幅度部分。
声谱图中如何产生图案
准备水印图
假设我们有像下面一样的一个水印图。

其中白色部分代表加强部分,黑色部分代表不需要加强部分,接下来要做的就是把这张图缩放到声谱图上的某个区域。
常见的嵌入方式
比较常见的嵌入方式有两类:一种在幅度上直接乘,另一种在 dB 域里叠加。
乘法加强
它的好处是比较顺着原音乐来,比如原本某个频段有声音,就在这个基础上增强;原本特别安静的地方,也不会突然冒出一大块很突兀的噪声。
代价也在这里,如果某个频段本来就很弱,那么你再怎么乘,图案也可能不够亮。比如一首很干净的钢琴曲,高频空白比较多,乘法增强出来的图案就未必看着明显。
dB 域叠加
另一种思路是在 dB 域里处理:
其中 可以理解成最大增强多少 dB。
这种方法和声谱图的显示方式更接近,所以图案通常更容易控制,想让白色区域亮多少,就给它加多少 dB。
也可以给水印设置一个能量下限:
其中 是基准亮度,它能保证图案不会完全被原音乐吞掉。
不过 dB 域增强也更容易翻车,加得太猛时音乐会出现明显的高频噪声,所以最好先用乘法增强做基础,再视情况少量补一点 dB 域叠加增强。
嵌入频段选择
频段选择很关键。放得太低,图案容易看见,但也容易被听见;放得太高,听感影响小,但一压缩可能就没了。
一个大致的经验是:
- 3k ~ 6k Hz: 保留率较好,但人耳敏感,容易听出痕迹。
- 6k ~ 12k Hz: 比较折中
- 12k ~ 18k Hz: 更隐蔽,但容易被压缩削弱
注意,如果音频采样率是 44100 Hz,那么最高可以表示的频率是采样率的 Nyquist 频率,即采样率的一半 22050 Hz。
图像选择
不能随便选择一张图片当作水印图,复杂照片、细小纹理、很细的字体,放到声谱图里通常效果不好。
更适合的图片是:
- 黑白或高对比图。
- 粗线条。
- 大字重文字。
- 简单 Logo。
- 轮廓清楚、细节少
常见预处理流程是:转灰度 → 自动拉伸对比度 → 缩放到目标区域大小 → 稍微做一点高斯模糊 → 必要时反色 → 上下翻转。
可直接采用以下函数将任意图片转为线稿图,并处理为 mask:
def image_to_mask(image_path, target_height, target_width):
bgr = cv2.imread(str(image_path), cv2.IMREAD_COLOR)
if bgr is None:
raise FileNotFoundError(image_path)
rgb = resize_to_height(cv2.cvtColor(bgr, cv2.COLOR_BGR2RGB), IMAGE_PREVIEW_HEIGHT)
gray = cv2.cvtColor(rgb, cv2.COLOR_RGB2GRAY)
hsv = cv2.cvtColor(rgb, cv2.COLOR_RGB2HSV)
lab = cv2.cvtColor(rgb, cv2.COLOR_RGB2LAB)
smooth = cv2.bilateralFilter(gray, 7, 48, 48)
median = float(np.median(smooth))
blur3x3 = lambda img: cv2.GaussianBlur(img, (3, 3), 0)
edge_gray = cv2.Canny(smooth, int(max(18, 0.55 * median)), int(min(150, 1.25 * median)), L2gradient=True)
edge_sat = cv2.Canny(blur3x3(hsv[:, :, 1]), 28, 92, L2gradient=True)
edge_a = cv2.Canny(blur3x3(lab[:, :, 1]), 18, 62, L2gradient=True)
edge_b = cv2.Canny(blur3x3(lab[:, :, 2]), 18, 62, L2gradient=True)
laplacian = cv2.convertScaleAbs(cv2.Laplacian(blur3x3(smooth), cv2.CV_16S, ksize=3))
_, edge_laplacian = cv2.threshold(laplacian, 24, 255, cv2.THRESH_BINARY)
adaptive = cv2.adaptiveThreshold(smooth, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 23, 6)
gradient = cv2.morphologyEx(smooth, cv2.MORPH_GRADIENT, np.ones((3, 3), np.uint8))
_, gradient_mask = cv2.threshold(gradient, 12, 255, cv2.THRESH_BINARY)
mask = edge_gray | edge_sat | edge_a | edge_b | edge_laplacian | (adaptive & gradient_mask)
mask = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, np.ones((2, 2), np.uint8))
mask = remove_small_components(mask, MIN_LINE_AREA)
mask = blur3x3(mask)
mask = cv2.normalize(mask, None, 0, 1, cv2.NORM_MINMAX).astype(np.float32)
mask = np.power(mask, MASK_GAMMA)
mask = cv2.resize(mask, (target_width, target_height), interpolation=cv2.INTER_AREA)
mask = cv2.normalize(mask, None, 0, 1, cv2.NORM_MINMAX).astype(np.float32)
mask = np.flipud(mask)
fade_len = max(1, target_width // 12)
fade = np.ones(target_width, dtype=np.float32)
ramp = np.linspace(0, 1, fade_len, dtype=np.float32)
fade[:fade_len], fade[-fade_len:] = ramp, ramp[::-1]
return mask * fade[None, :]处理可以得到以下图像,为方便展示没有上下翻转,之后的嵌入演示也将以该图片为例。

处理流程
graph TD
A[读取音频] --> B[做 STFT,得到复数频谱]
B --> C[拆出幅度和相位]
C --> D[读取水印图片,处理成 mask]
D --> E[选择时间范围和频率范围]
E --> F[用 mask 修改频谱幅度]
F --> G[保留原相位,重建复数频谱]
G --> H[inverse STFT,还原成波形]
H --> I[导出音频,打开声谱图检查]
这里有一个很实用的简化:只改幅度,不主动改相位。
原始频谱可以写成:
修改幅度后变成:
也就是说, 换成了 ,相位 仍然用原来的。
代码实现
仅给出基础处理函数:
def embed_mark(
audio_path,
image_path,
output_path,
start_time=10.0, # 开始时间 (s)
duration=2.32, # 持续时间 (s)
f_min=8000, # 最低频率 (Hz)
f_max=16000, # 最高频率 (Hz)
strength=0.4, # 强度
n_fft=4096, # 决定频率的精细度
hop_length=512, # 决定时间的精细度
):
audio_path = Path(audio_path)
image_path = Path(image_path)
output_path = Path(output_path)
# STFT
y, sr = librosa.load(audio_path, sr=None, mono=True)
stft = librosa.stft(y, n_fft=n_fft, hop_length=hop_length)
magnitude = np.abs(stft)
phase = np.angle(stft)
freqs = librosa.fft_frequencies(sr=sr, n_fft=n_fft)
times = librosa.frames_to_time(
np.arange(magnitude.shape[1]),
sr=sr, hop_length=hop_length, n_fft=n_fft,
)
freq_start = np.searchsorted(freqs, f_min)
freq_end = np.searchsorted(freqs, f_max)
time_start = np.searchsorted(times, start_time)
time_end = np.searchsorted(times, start_time + duration)
if freq_end <= freq_start or time_end <= time_start:
raise ValueError("无效的时间或频率范围")
img = Image.open(image_path)
mask = np.asarray(img, dtype=np.float32) / 255.0
# 融合
region = magnitude[freq_start:freq_end, time_start:time_end]
magnitude[freq_start:freq_end, time_start:time_end] = (
region * (1.0 + strength * mask)
)
# ISTFT
new_stft = magnitude * np.exp(1j * phase)
y_out = librosa.istft(new_stft, hop_length=hop_length, length=len(y))
# 归一化音量
peak = np.max(np.abs(y_out))
if peak > 0:
y_out = y_out / peak * 0.98
sf.write(output_path, y_out, sr)完整版本如下: spectrogram_watermark.py
该版本支持自动处理图片,频率配置,自动配置参数,导出水印图和水印音频等功能。
效果展示
设定:
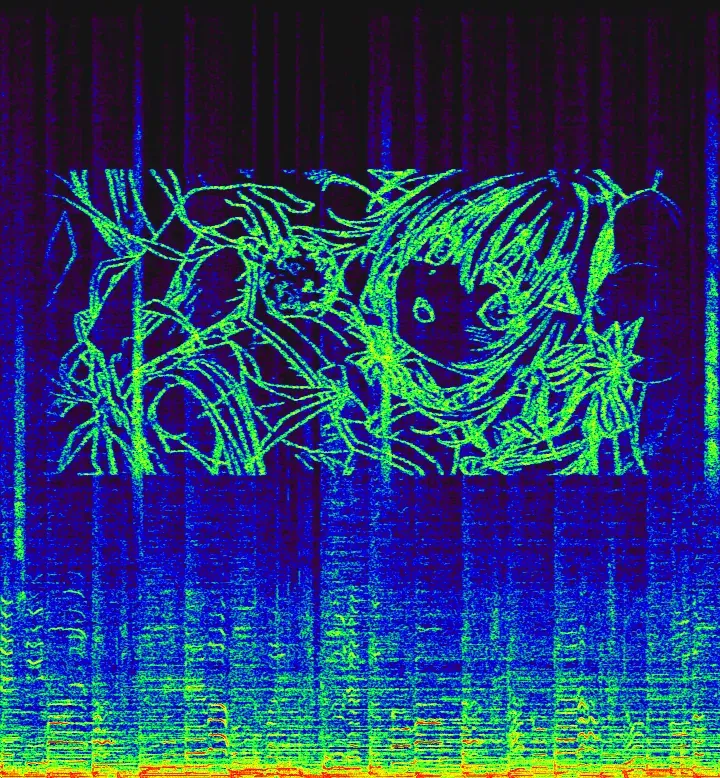
FREQ: 8k ~ 16k HzN_FFT: 4096HOP_LENGTH: 256OVERLAY_MODE: adaptive_add
导出音频后使用 Foobar 2000 查看频谱,参数设置为 Scale: Linear, FTT size: 4096,可明显地观察到嵌入的水印图像:
如果运行后图像不太正常可以从这几个方面调整:
- 图案太淡: 增大
MIX_GAIN - 图案比例不对: 更改
HOP_LENGTH或FREQ_BANDWIDTH